Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

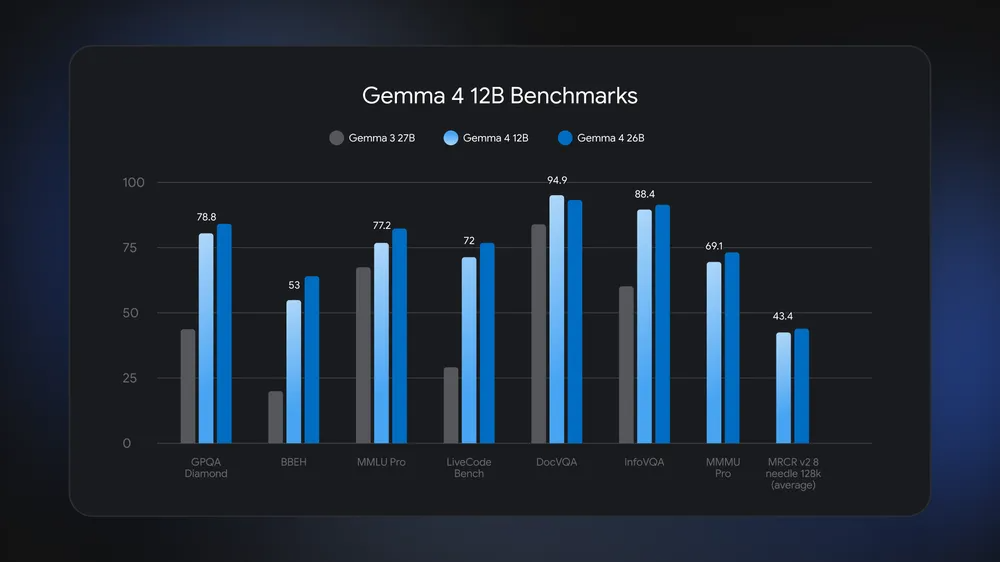
Gemma 4 12B is possible as a model with 26 billion parts.
Credit: Google
Gemma 4 12B is possible as a model with 26 billion parts.
Credit: Google
Google says the new model can handle the complex thinking and workflows that previously required the larger Gemma models. Despite the small parts count, the Gemma 4 12B comes with a newly developed feature Multi-Token Prediction (MTP) notes.who take advantage of unused channels to calculate possible future signals. The result is great speed and performance. Google has released optional MTP models for other Gemma 4 models, but this is the first to have MTP out of the box.
The Gemma 4 12B is also very useful thanks to the innovative multi-product method. The Gemma 4 family is very traditional, accepting text, audio, or images as input. Most gen AI models – including some Gemma 4 models – use dedicated encoders to process non-encoded inputs and send those to LLM. This works fine, but increases latency and memory usage.
With the new example of the center of its weight, Google has implemented a vision setting unit, which has a single matrix multiplication and placement, which allows the data to go to the LLM with the correct recognition of the place. This eliminates the need for a central encoder. For audio, there is no encoding at all. Developers have created a way to view raw signals in containers used for tokens.
If you want to see the new version of Gemma 4, it is available without downloading using tools like LM Studio, Google AI Edge Galleryetc. But the whole idea with the Gemma 4 12B is that you can drive it locally and for your own purposes. If you have RAM, sample weights are available for immediate download Kaggle and Hugging Face. It’s just shy of 18GB.


