Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

Another day, another kind of AI from Google. This time, Google DeepMind released a new member of the Gemma 4 model open familybut it is really different from the rest of the group. DiffusionGemma does not generate linear outputs like most AI models. In fact, it can output a whole group of text simultaneously. Google says so this makes it faster and more efficient when using local hardware such as Nvidia DGX or a modest gaming GPU.
Most AI models are designed to be autonomous – they process words from left to right one character at a time. DiffusionGemma has a lot in common with the image creation models, which start with static and then mock them up to create what you want. This model takes a set of tokens that run the screen multiple times to generate potential tokens and use those to control the comparison of others. At the end of the process, the model finalizes its output in one large block – the “denoised” text canvas.
DiffusionGemma is the largest of Google’s open source models. It’s a Mixture of Experts (MoE) model with 26 billion parts, but only 3.8 billion are activated during a thought process. This means that it should fit into the 18GB section of a high-end GPU. When testing with an RTX 5090, DiffusionGemma spits out around 700 tokens per second. With one Nvidia H100 AI accelerator, DiffusionGemma can generate 1,000+ tokens per second. That’s about four times the output of the same autoregressive Gemma model.
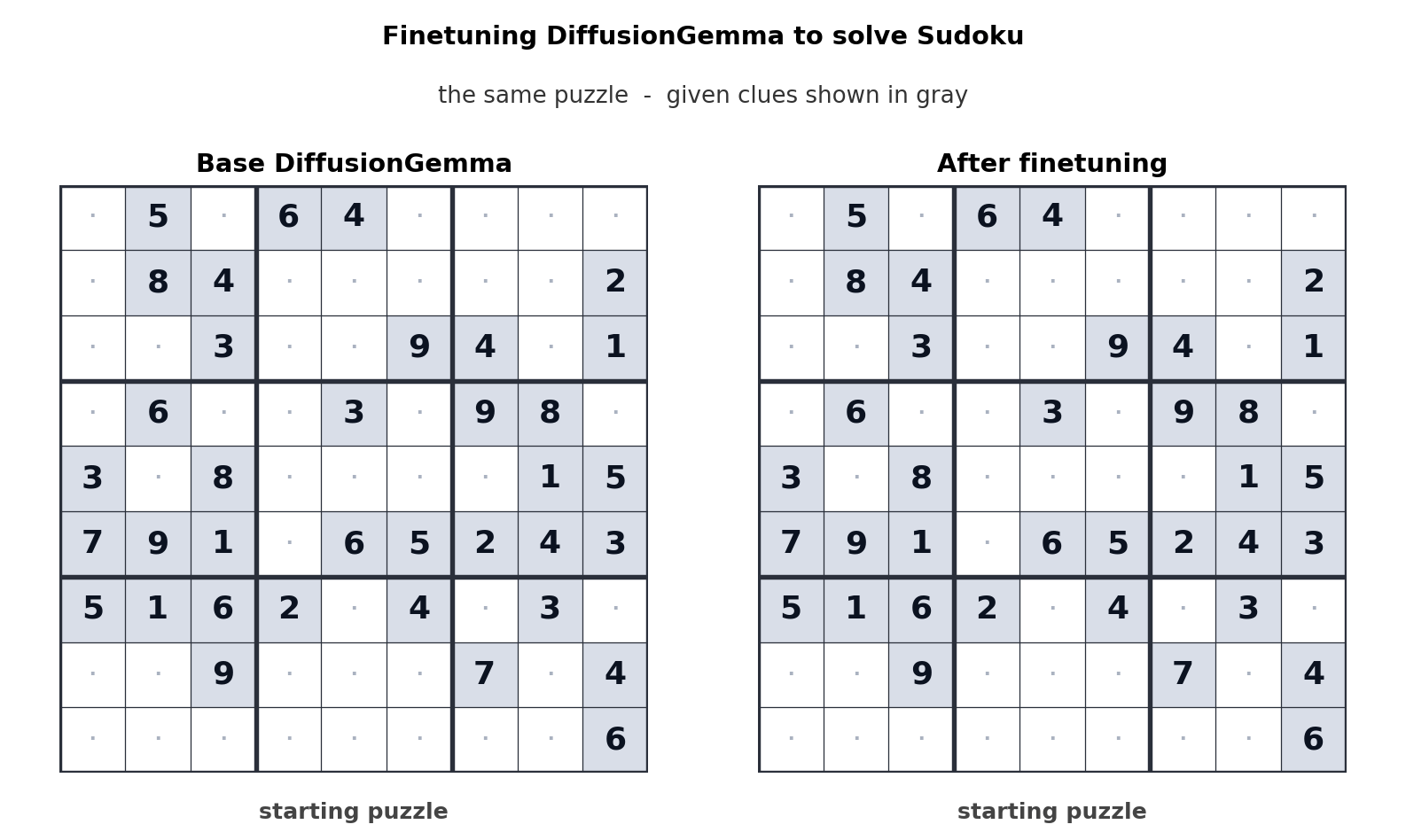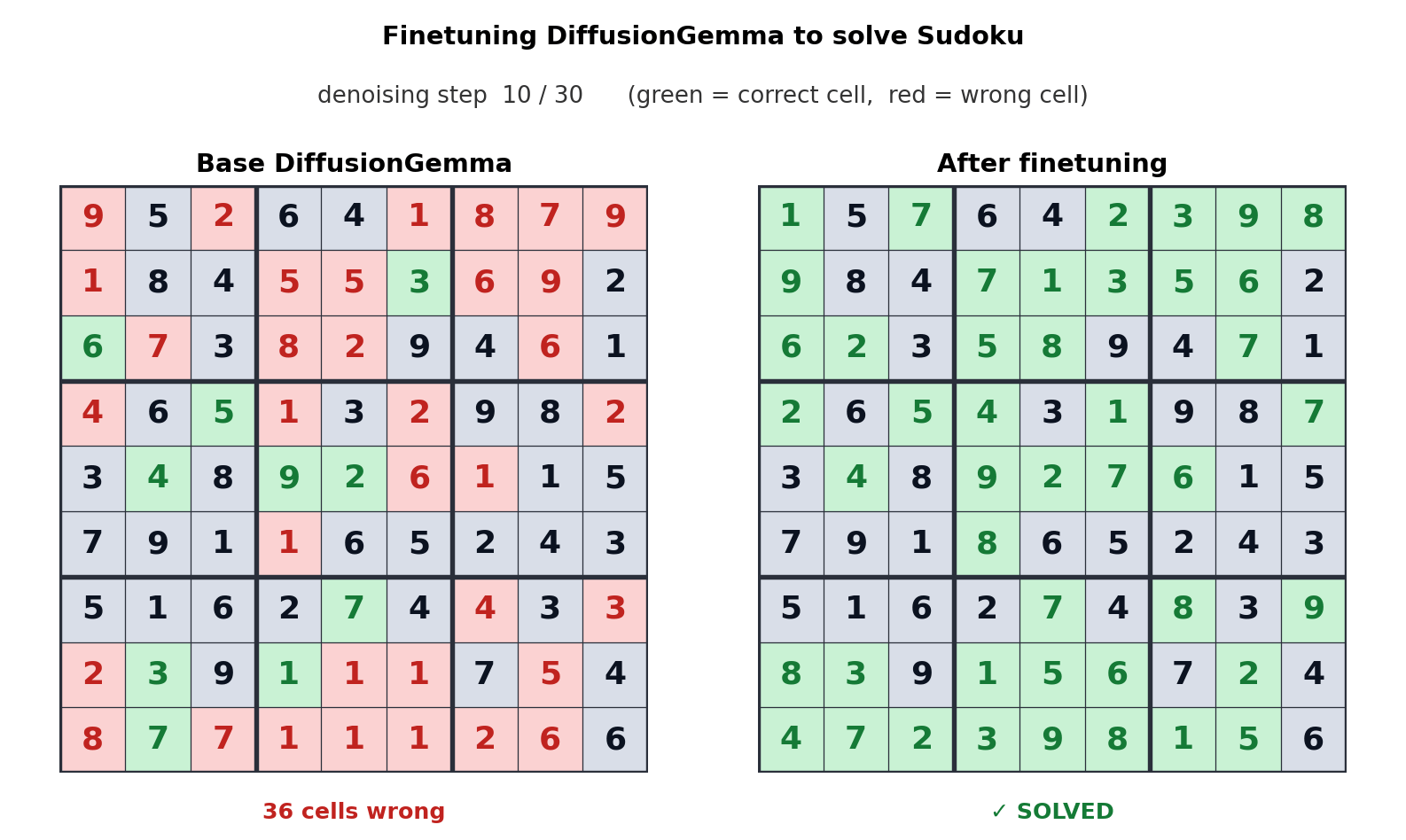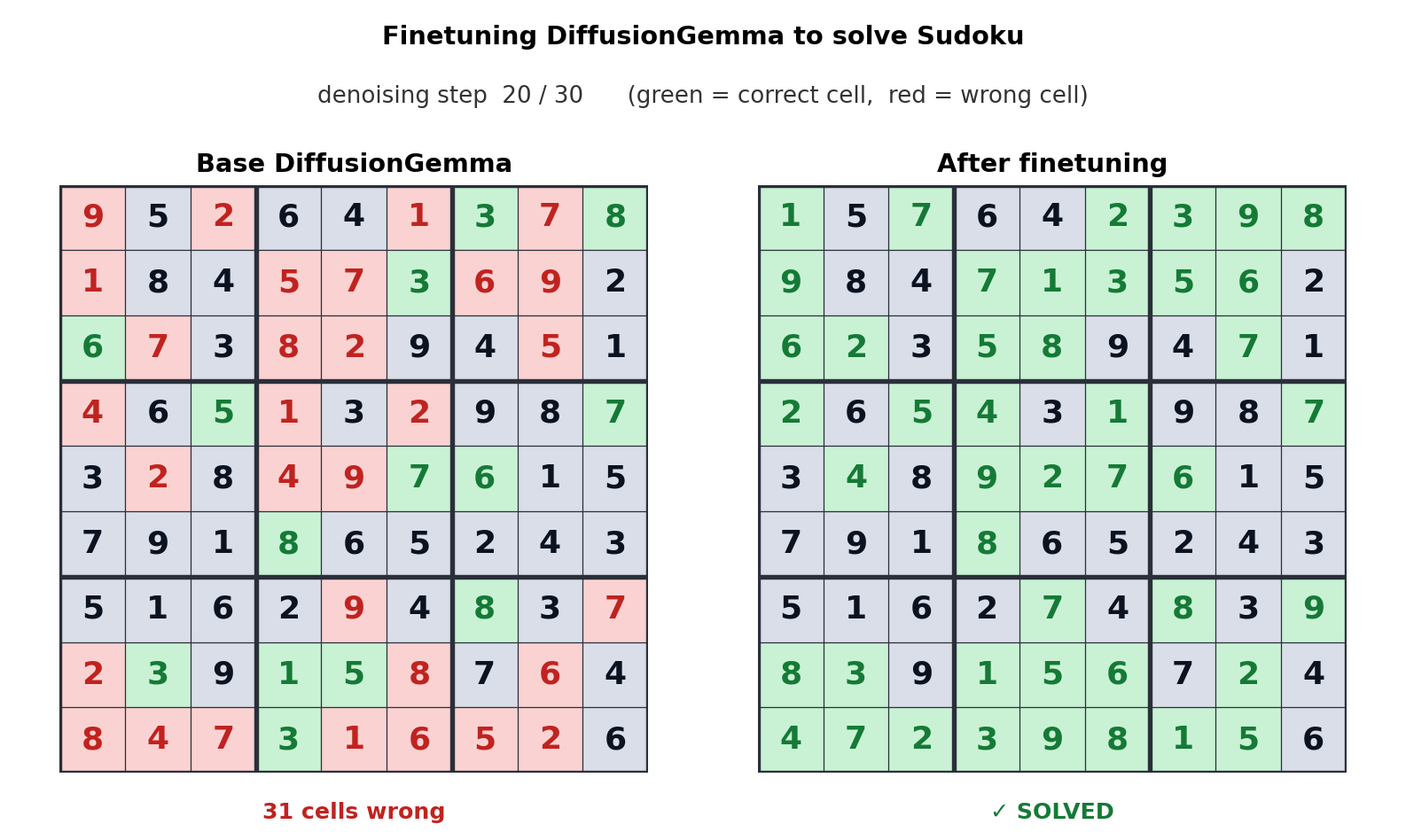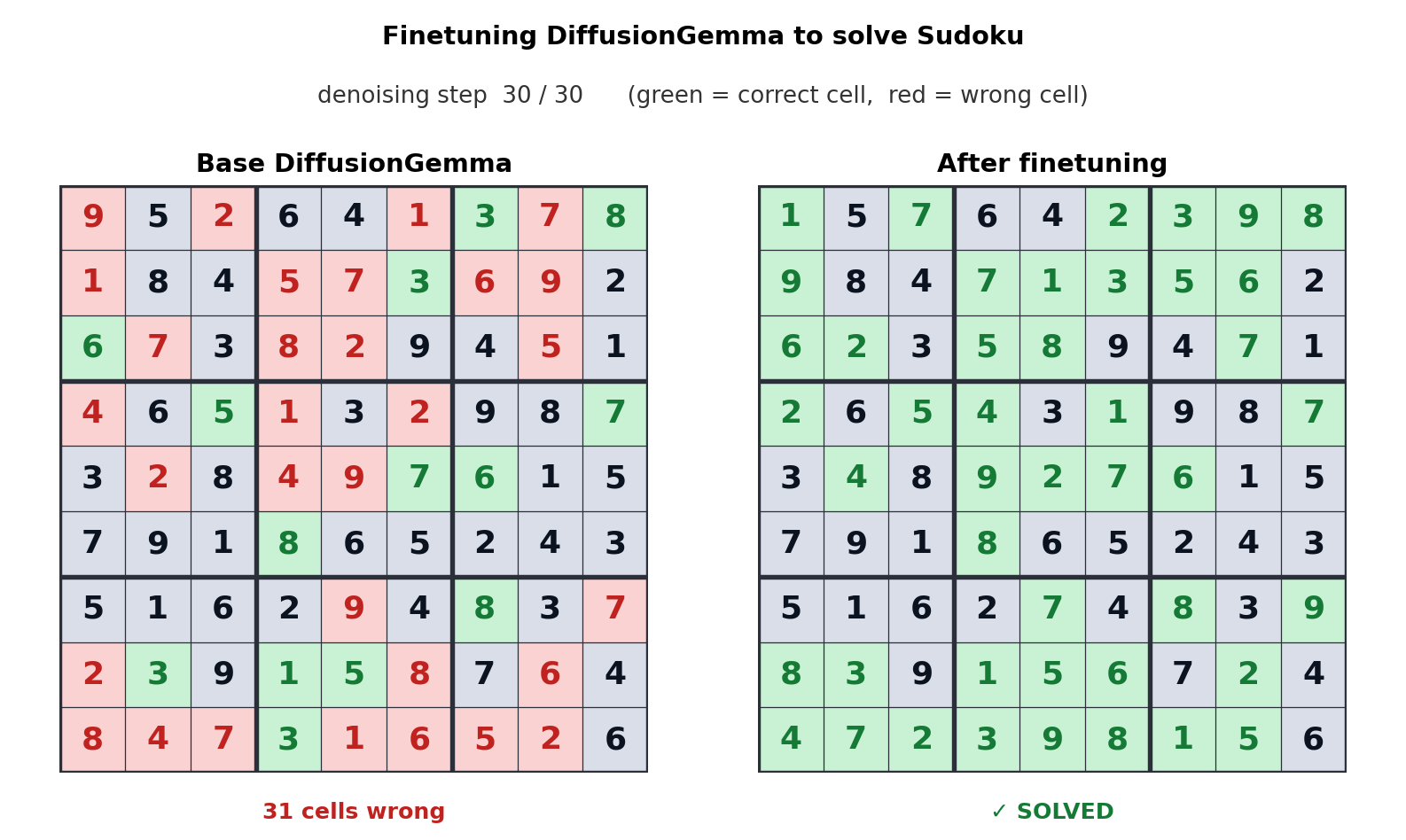
This token generation method switches the bottleneck from memory bandwidth to compute, generating up to 256 tokens in parallel. Google says this provides a measurable improvement in non-linear tasks such as linear transformation, cell sequencing, and mathematical mapping. The videos above show how DiffusionGemma was adapted to solve Sudoku puzzles, which is a very difficult task for conventional AI models because each token depends on future tokens. DiffusionGemma’s ability to continuously process large tokens makes this easy.



