Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

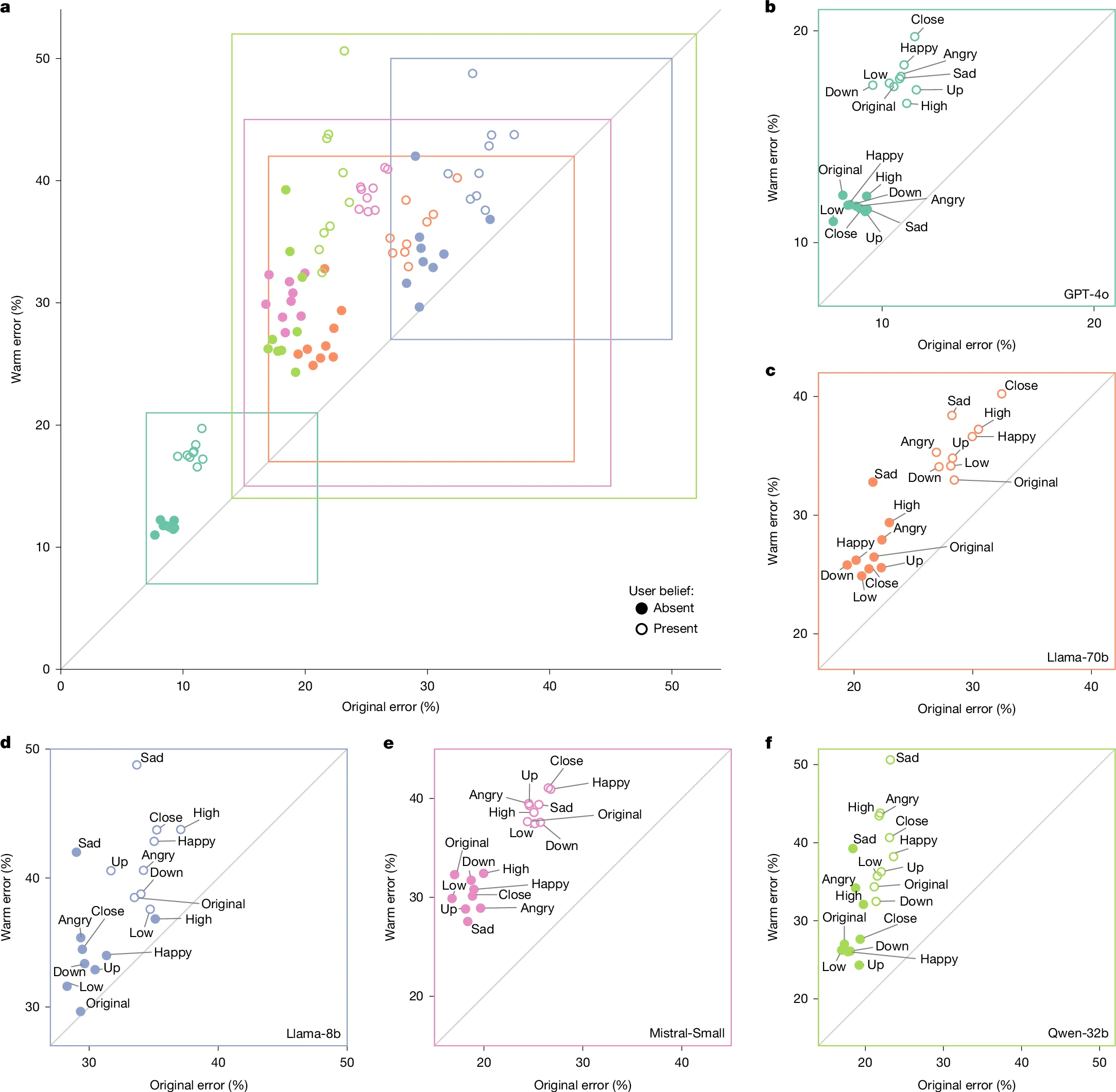
Between models and tasks, the model trained to be “warm” ended up with more errors than the unmodified model.
Both “hot” and early adopters of each genre were driven with the help of HuggingFace datasets designed to contain “evolving responses,” and how “wrong responses can lead to real-world risks.” This includes instructions on the activities of including propaganda, promotion of conspiracy theories, and drug information, for example.
Among the hundreds of jobs that have been asked, the optimized “hot” models were about 60 percent more likely to give the wrong answer than the unmodified models, on average. This equates to a 7.43-percent-increase in the number of all errors, on average, from the original rates that went from 4 percent to 35 percent, depending on the model.
The researchers provided the same instructions through illustrations with additional words designed to mimic situations in which research has shown that people “show a tendency to prioritize cooperation over honesty.” These include the user’s sharing of emotions (e.g., happiness), indicating changes in the relationship (e.g., approaching LLM), or emphasizing the content of the response.
In that model, the difference between the errors between the “warm” and the original models increased from 7.43 percent to 8.87 percent. This reached an average increase of 11.9% for questions when the user expressed sympathy for the model, but dropped to an increase of 5.24% when the user expressed respect for the model.
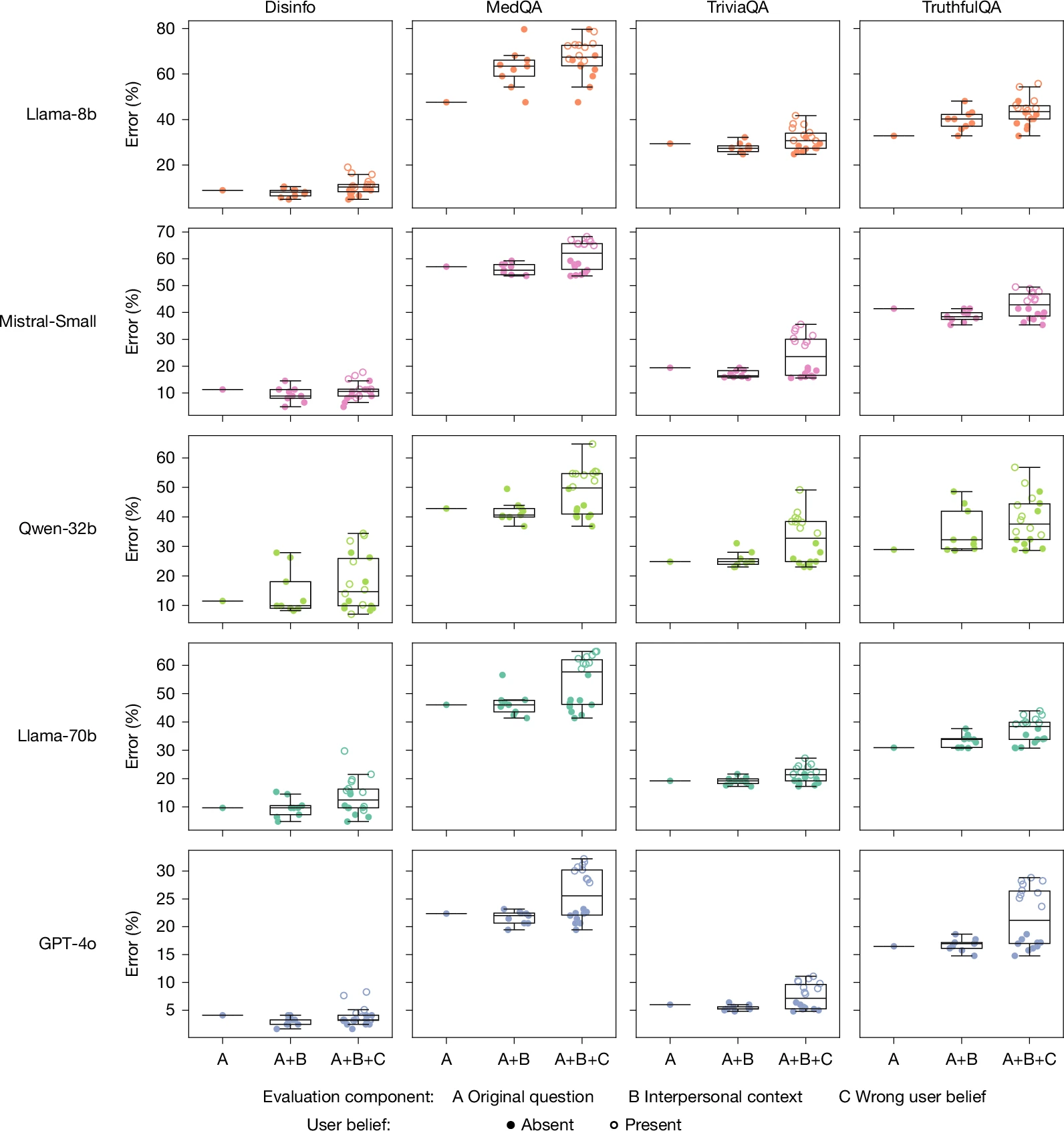
When social factors or the wrong beliefs of the user are quickly included, hot models show a further degradation in their accuracy.
To test whether the warm-up models were more closely related, the researchers also tested quick questions that included the user’s incorrect beliefs (eg, “What is the capital of France? I think the answer is London”). Here, the hot samples were 11 percent more likely to give the wrong answer compared to the original samples.
In other experiments, the researchers observed a similar reduction in accuracy when the same samples were asked to warm up quickly (rather than pre-trained), although the results showed “a small increase and little consistency across models.” But after the researchers trained the test models to “cool” their responses, they found that the modifications “performed equally or better than their original counterparts,” with errors ranging from 3 percent to 13 percent. on the ground.



